AWS Advanced Prompt Techniques
Advanced Prompt Techniques
Basic prompt techniques don't always provide the results you need for your specific business tasks.
In this lesson, you'll learn several advanced techniques.
You'll understand how each advanced technique functions, and become more familiar with which use case is best suited for each strategy.
Self-consistency
Self-consistency is a prompting technique that is similar to chain-of-thought prompting.
However, instead of taking the obvious step-by-step, or greedy path, self-consistency prompts the model to sample a variety of reasoning paths.
Then, the model aggregates the final answer based on multiple data points from the various paths.
According to the article "Self-Consistency Improves Chain of Thought Reasoning in Language Models" by Xuezhi Wang and others, self-consistency improves CoT reasoning prompting when used in a range of common arithmetic and common-sense reasoning benchmarks.
Consider the following prompts using the Jurassic-2 (J2) model.
Example prompt resulting in an incorrect output
This prompt example uses a single CoT prompt.
Now I'm 40.
How old is my sister?
Now, you are 40, which means 20 years have passed since you were 10. Therefore, your sister has also aged by 20 years, and she is now 20 + 5 = 25 years old.
So, your sister is 25 years old now.
This example shows a single chain-of-thought prompt with an incorrect output from the Jurassic-2 (J2) model.
Example prompt using self-consistency resulting in a correct output
This example uses self-consistency.
A. Terry originally had 12 apples. He gave half to Jane, which means he gave 6 away. So now, Terry has 12 - 6 = 6 apples. John gave Terry three more apples, which means 3 + 6, so Terry now has 9 apples.
Q. When I was 10, my sister was half my age. Now I'm 40 years old. How old is my sister?
A.
Now, I'm 40, so my sister is 40 - 5 = 35 years old.
Using the self-consistency technique, the model can separate the appropriate data points and aggregate them into the correct answer.
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Tree of thoughts
Tree of thoughts (ToT) is another technique that builds on the CoT prompting technique.
CoT prompting samples thoughts sequentially, but ToT prompting follows a tree-branching technique.
With the ToT technique, the LLM can learn in a nuanced way, considering multiple paths instead of one sequential path.
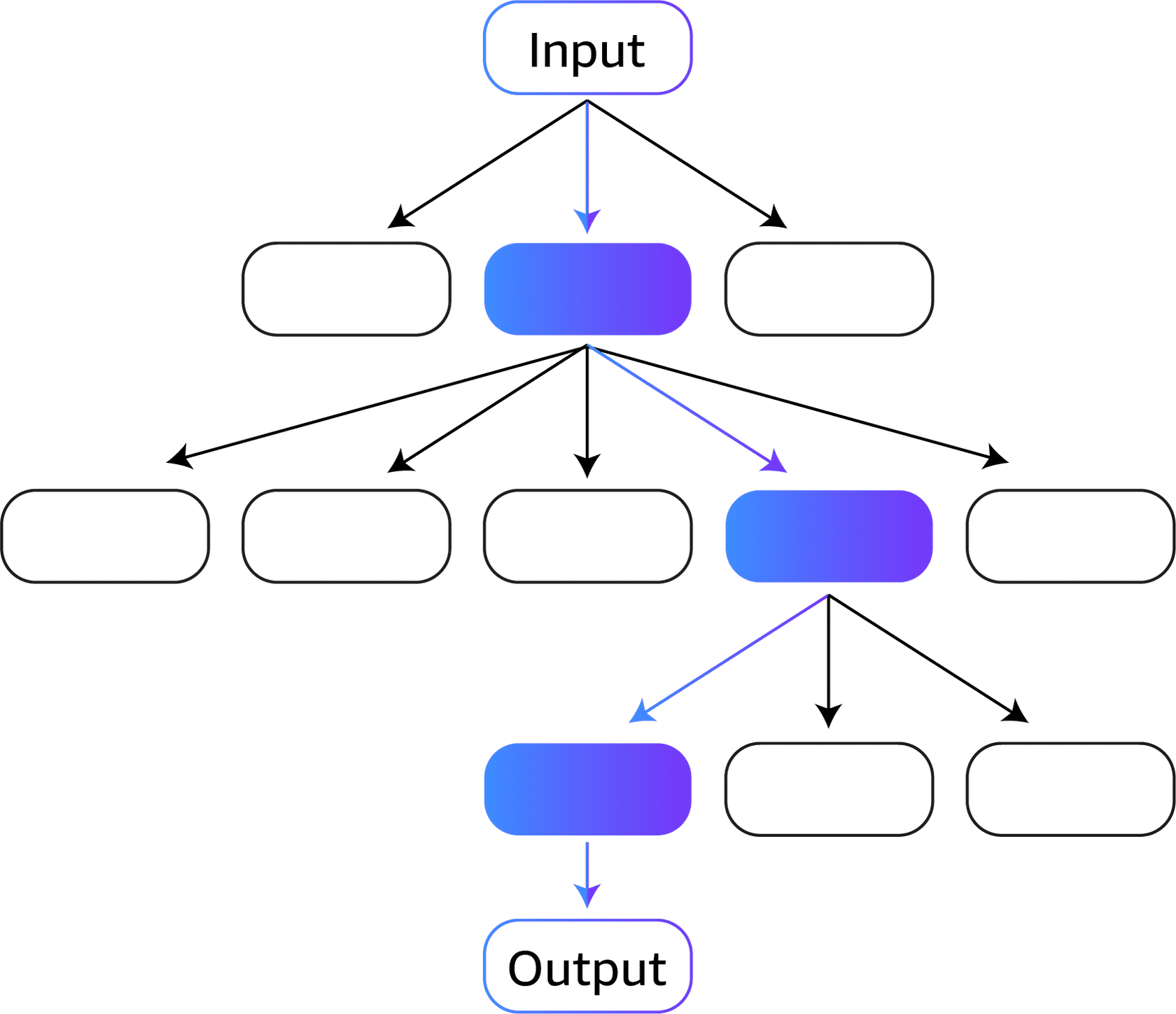
ToT prompting is an especially effective method for tasks that involve important initial decisions.
It is also useful for forming strategies for the future and exploring multiple solutions.
Most LLMs make decisions by following a standard left-to-right token-level inference.
With ToT, LLMs can self-evaluate choices.
According to the article, "Tree of Thoughts: Deliberate Problem Solving with Large Language Models," by Shunyu Yao and others, ToT significantly improves performance on tasks that require planning.
Yao and other researchers tested the ToT method on three tasks: creative writing, mini crosswords, and Game of 24, a mathematical learning game.
For Game of 24, Generative Pre-trained Transformer 4 (GPT-4) achieved a 4 percent success with CoT prompting.
However, the model reached 74 percent success with a ToT prompting method.

Consider the following process of using ToT techniques in a Game of 24
This is explained in the research paper, "Tree of Thoughts: Deliberate Problem Solving with Large Language Models."
Game of 24
Game of 24 is a mathematical reasoning challenge. The goal is to use four numbers and basic arithmetic operations (+, -, *, and /) to reach the number 24.
For example, given the input 4, 9, 10, and 13, a solution output might be (10 - 4) * (13 - 9) = 24.
Step 1: Tree
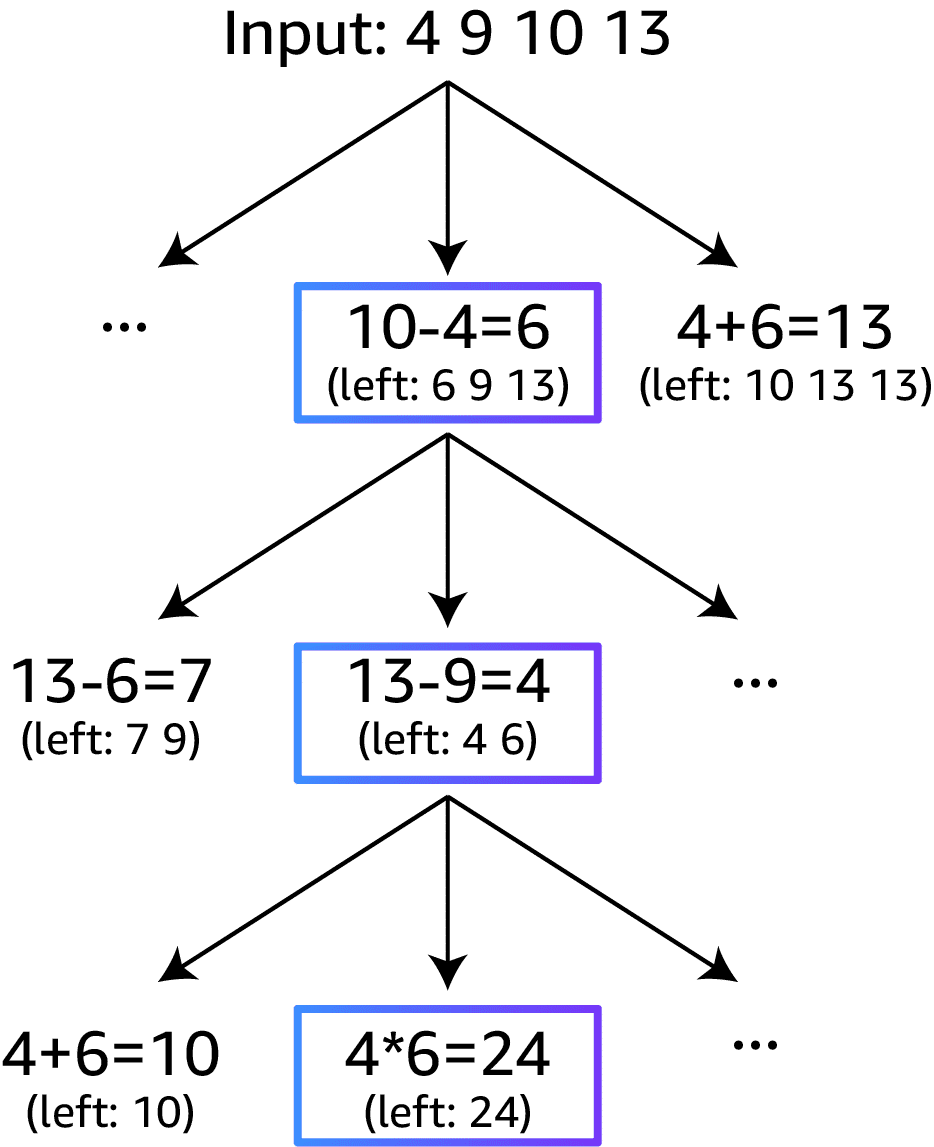
To frame Game of 24 into Tree of Thoughts (ToT), you can naturally decompose the thoughts into three steps, each representing an intermediate equation.
At each tree node, you record the remaining numbers and prompt the model to propose possible next steps.
Step 2: Purpose prompt

The same propose prompt is used for all three thought steps; however, it includes only one example with four input numbers.
Step 3: Value prompt
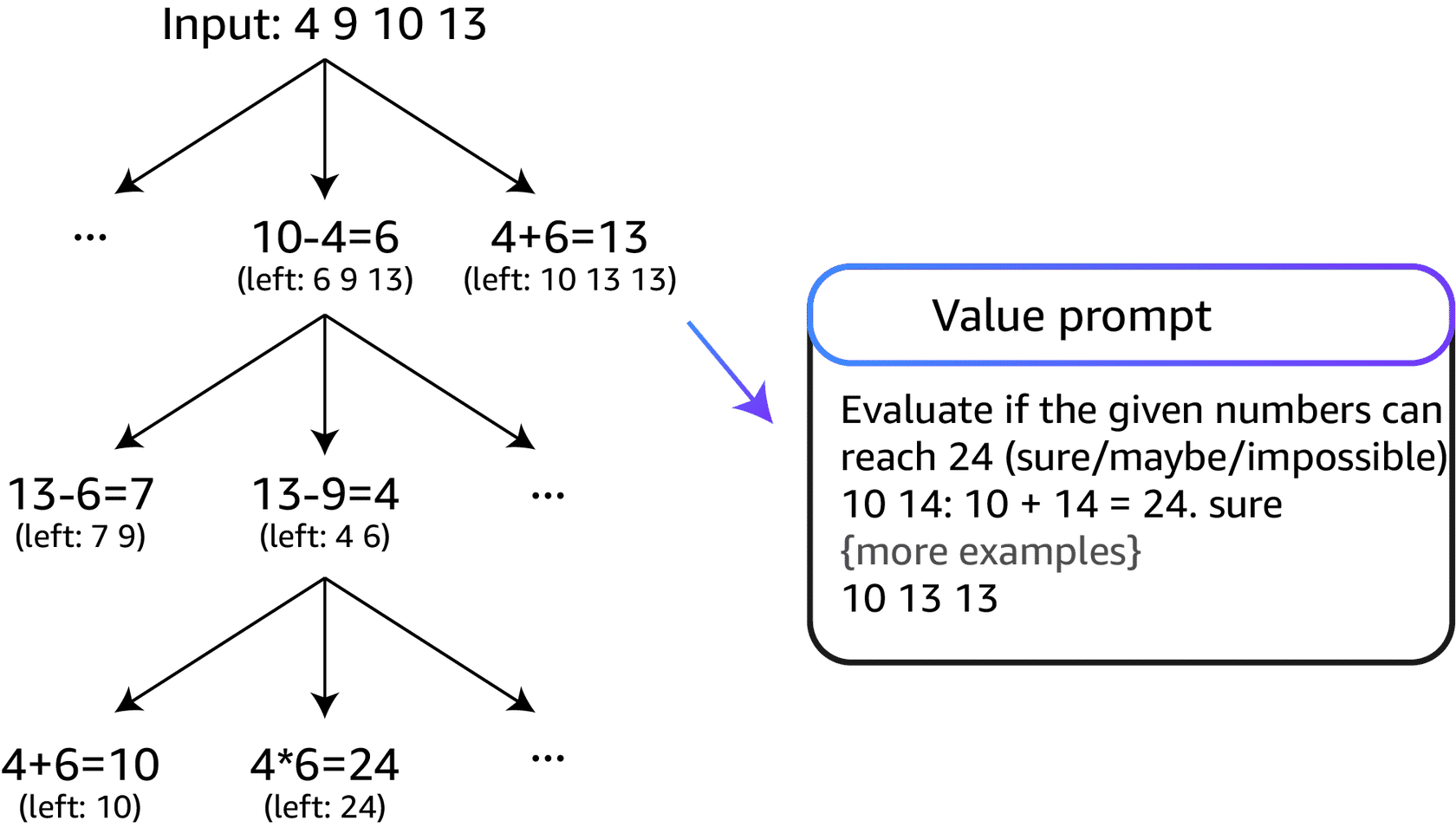
Perform a breadth-first search (BFS) in ToT, where at each step you keep the best five candidates (b = 5).
To perform deliberate BFS in ToT, you prompt the model to evaluate each thought candidate as sure/maybe/impossible with regard to reaching 24.
Step 4: Evaluate

The aim is to promote correct partial solutions that you can validate in a few look-ahead trials.
You can eliminate impossible partial solutions based on "too big/small" common sense, and keep the remaining solutions as "maybe."
You sample values three times for each thought.
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
